大一下有幸选拔进入了具身智能项目制实验班,大二上便开始了具身智能项目的研究,由于这是一篇对我大二上这一学期在项目实践上学习到和使用到的技术的总结,所以煽情的话放到我的life系列来说吧。接下来我就来介绍一下,在这个项目中所用到的关键技术和每一步的进展,希望几年之后再看到这篇文章时,也就不会面对19岁前半年的成长心有不甘了。当然了,希望能有具身智能相关方面的大佬多加指导,欢迎大家一起讨论。
项目总览与成果
一、整体配置和目标
在整个项目中,我们使用的是史河机器人EA200,机械臂是kinova gen3,项目的整体实现目标是利用kinova机械臂和自己设计的抓取工具来进行拆药板并将药品分装。

二、本学期目标
而我们这个学期的目标主要分为四部分,总结来说就是识别药板后将药板抓取放到指定黑框里,我们组一共四个人,于是将其分为了四部分:
- 1.设计特殊化抓取工具(wyf)
- 2.识别药板并根据抓取工具完成对抓取坐标的发送(本人)
- 3.机械臂的运动规划和控制(klr)
- 4.识别黑框并发送坐标,以及手眼标定(qgx)
这里我负责的是第2部分,听起来好像挺简单的,事实上,对于一个之前从来没接触过相关内容的清澈愚蠢大学牲来说,从零开始去在实机上完成这样一个完整的运动流程,以这样一个项目来作为科研的开端,其实难度并不小。所幸,挺喜欢这东西,也就自然很愿意研究这东西,再得益于组员的大力配合,因此进展还算比较顺利。
三、成果
目前,我们已经可以完整的从识别药板开始,发送药板位姿给机械臂,机械臂进行运动规划并到达指定抓取位置,再移动到识别到的黑框的位置,最后返回home。现在我们还差把抓取工具集成到机械臂上这一步,不过这个我们组的wyf(负责第1部分的同学)已经通过3D打印将抓取工具打印出来,组装电机并安装在了右臂上,只是网络连接还有点小问题,还在调试。
总体来说,作为组长,我已经很满意了,整个项目100%的代码都是我们自己搞定的,每一步的流程也是我们一步一步自己摸石头过河摸出来的,并没有什么官方文档或者成熟的文案去供我们参考,所以现在想想大家真的还都挺厉害的。一开始我们都没有想到能做到这一步,一来是我们的课都不少,这个项目都是挤时间去做;二来是在实机上去部署,去衔接,总是会有大大小小意想不到的而且不知从何入手的bug。不过,为者常成,行者常至,我们还是拿下了。
这里也要特别感谢付学长和陶学长的帮助和指导,以及每周都能抽时间来带我们开组会讨论进展。
项目历程和技术分享
以下分享的是本人在项目中完成的任务的内容。整个流程对于linux系统的基础命令以及对ROS2基础的要求还是挺高的(这得益于我在9月份刚开学的时候没啥事玩了玩一个月的ROS2,所以现在用ROS2几乎没什么障碍)
一、环境配置
我们整个的项目是建立在ROS2的基础上的,因此需要安装linux系统,这里我安装的是双系统ubuntu22.04,ROS2的版本选择的是humble,编程的IDE选择的是vscode,并安装了anaconda环境(其实miniconda就足够了),同时在我的github主页也可以看到我们项目的代码,过一段时间会上传完整。
二、安装相机的SDK以及驱动
我在自己的电脑上连接的是Intel Realsense深度摄像头D435i

包含一个RGB相机、两个红外相机以及一个红外发射器,此外还有一个IMU单元,深度成像原理是红外成像。
1.安装Intel Realsense SDK2.0
安装依赖
sudo apt install libudev-dev pkg-config libgtk-3-dev
sudo apt install libusb-1.0-0-dev pkg-config
sudo apt install libglfw3-dev
sudo apt install libssl-dev下载源码
git clone https://github.com/IntelRealSense/librealsense.git
cd librealsense添加权限
sudo cp config/99-realsense-libusb.rules /etc/udev/rules.d/
sudo udevadm control --reload-rules && udevadm trigger 启动相机
colcon build
realsense-viewer2.安装realsense-ros
当然,现在我们仅仅是启动了相机,但是要将相机的数据作为ros2话题发布出去,就需要完成realsense-ros驱动的安装。
创建工作空间并下载源码
mkdir -p ~/realsense_ws/src
cd ~/realsense_ws/src
git clone https://github.com/IntelRealSense/realsense-ros.git
git clone https://github.com/pal-robotics/ddynamic_reconfigure.git编译并启动launch文件
cd ..
colcon build
source install/setup.bash
ros2 run realsense2_camera rs_launch.py三、将yolov8部署到自己的ws中
1.安装yolov8代码
安装yolov8及依赖
pip install ultralytics
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu126 注意这里的cuda驱动要根据你的显卡来确定cuda驱动的版本,这个可以到英伟达官网去查询。
2.部署相关环境
安装必要的系统依赖
sudo apt update
sudo apt install -y python3-pip python3-colcon-common-extensions git
sudo apt install -y ros-humble-cv-bridge ros-humble-image-transport ros-humble-rmw-cyclonedds-cpp
sudo apt install -y libopencv-dev安装ROS2 Python接口
pip install rclpy
pip install sensor_msgs
pip install opencv-python接下来创建自己的工作空间以及python包
mkdir -p ~/vision_ws/src
cd ./vision_ws/src
ros2 pkg create --build-type ament_python simple_detector --dependencies rclpy sensor_msgs cv_bridge image_transport
cd ..
colcon build3.初步检测
这里最终的检测代码已经push到github主页中,将检测代码添加到vision_ws/simple_detector/simple_detector目录下。
当然,不要忘记在setup.bash中添加node
entry_points={
'console_scripts': [
'simple_detector_node = simple_detector.simple_detector_node:main',
],
}四、训练模型并使用自己训练出来的模型进行初步检测
1.收集照片并完成标注
为什么要训练模型呢,道理很简单,因为yolov8模型识别不出来药板,网上也没有现成的(bushi)。
我在网上收集了40张的药板的照片,最好是背景多元化一点,然后这里我使用的是学长推荐的trax_label软件进行自动的数据标注(2D框标注就足够了),这个自动标注的效果还是很好的,可以节省很大的功夫,但是注意置信系数要调整到一个比较合适的值,什么值合适呢,我觉得这个就得自己微调一下了,我记得当时在这个点上我就调了一两个小时。最后会自动给你生成一个dataset文件夹,其中包括images和labels,还会有一个classes.txt。注意把这个dataset文件夹放在src/simple_detector路径下。
然后理论上我们就可以进行训练模型了,但是吧,如果你现在就用这40张照片去训练模型的话,最后出来的检测效果就会非常差,置信系数都调到0.95了,模型还是会把你的键盘也识别成药板(别问我怎么知道的),所以接下来我们就要进行一些处理。
大体上分为两个处理:
首先就是根本上来说还是图片量太少了,但是我又没有很多的时间去找大量的图,所以这里需要进行数据增强,我在src/seimple_detector/tools下面搞了一个数据增强代码augment_dataset.py,增强的原理大致就是水平翻转、亮度/对比调整、高斯模糊、缩放+平移(仿射变换),并在变换后裁剪并修正边界框,丢弃被破坏得太小或几乎不可见的 box(避免生成错误标签)等等,最后达到的效果是每张照片的基础上又多生成了7-8张照片,好了,这回的体量是够够的了。
不过,事实证明,这个识别结果还是很糟糕,我就想到了加入非药板负样本集的办法,因为本身我们的识别背景就不复杂,那么如果模型能把yolov8里面可以识别出来的那些日常物品都视为非药板的话,那么检测精度就会大幅提升。那么我在datasets下面放了一个negatives数据集,再下载yolov8自带的COCO128数据集(包含 128 张多类图片)放到里面;
OK,接下来我们就可以开始训练模型了。
2.用数据集训练模型
在训练模型之前,必须要说一点,强烈建议用GPU来跑,用CPU的话会很慢很慢。
先检查一下你的电脑是否有可用的GPU以及驱动,这里就可以看到系统驱动支持的CUDA版本了
nvidia-smi查看python版本
python3 --version到pytorch官网上选择你的 Python 版本和 CUDA 版本,它会告诉你正确的安装命令。
安装完再验证一下
python3 -c "import torch; print(torch.cuda.is_available())"如果结果是True,那就证明GPU已可用。
在simple_detector/simple_detector/tools下建立训练模型的文件train_drugboard_with_negatives.py,这里的epoches我设置的是150(用GPU还是很快的),而batch我设置的是16,用GPU跑还是挺快的,1个小时左右差不多就能跑完。
yolo detect train \
data= ~/vision_ws/src/simple_detector/dataset/data.yaml \
model=yolov8m.pt \
epochs=150 \
imgsz=640 \
batch=16 \
device=0 \
lr0=0.002 \
lrf=0.1 \
weight_decay=0.0005 \
momentum=0.937 \
cls=1.5 \
box=7.5 \
patience=30 \3.使用自己训练出来的模型进行初步检测
最后再把检测节点中的模型替换一下,注意路径不要写错,然后再进行启动我的检测节点就可以看到比较好的检测效果了。
这里我还进行了一些处理,由于我们最后的矩形药板要放到矩形黑框里,所以不可避免的就是对角度的检测,那么这里为了能在窗口中清晰的显示出来,我就采用了opencv自带的边缘检测技术,并采用最小矩形法勾画出了药板的矩形框。然后再调整输出的坐标是相对于相机的x,y,z坐标以及矩形框主轴与图像界面x轴正方向的的角度。
最后的检测结果大致是这样的:
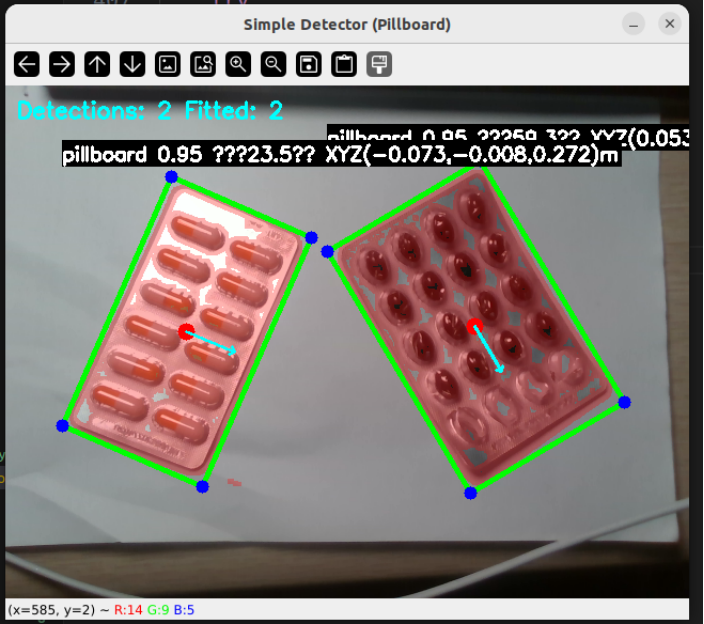
那么在我自己的电脑上的部分基本就是这样了,下面我们就要进行实机部署了,本来以为实机部署会很麻烦,会有很多问题,但事实证明接下来的进展还是比较顺利的。
五、上实机部署
1.完成对头部摄像头D455的调用
在研究院的主机上已经安装了相关相机的SDK以及realsense-ros驱动,因此此处直接启动相机节点即可。
ros2 launch realsense2_camera rs_launch.py可以使用以下命令来看是否成功发布话题
ros2 topic list也可以查看话题内容
ros2 topic echo /话题名称2.代码部署
在研究院的主机上创建一个自己的ws,然后将每个人所需要的代码放到里面,然后统一colcon build一下就可以了,当然代码结构也要整合好。
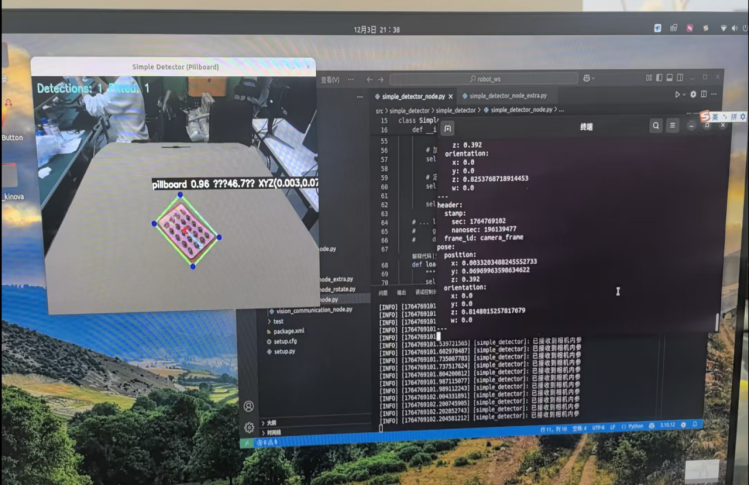
当然,我在这里也尝试了一下自己的药板检测节点能否启动。这里就出现了一些问题,启动节点是没什么问题的,但是启动之后过2-3秒就会死机,后来我排查了好久,确定了是我的节点的问题:默认使用GPU进行yolo推理,进行边缘检测和矩形框的绘制,识别和发送消息的频率过高,这几点都会占用很高的内存,导致内存直接爆了。
所以我调整了一下发送的频率,并设置用CPU跑,最后占用的内存大约是原来的1/5,目前启动节点是没有任何问题了。
3.了解运动规划和执行节点
这个部分是klr同学负责的,可以说完成的还是很好的,我进行节点对接的时候基本上没有什么问题。
这里我主要是根据klr给我提供的命令行,去启动运动控制节点,再发送A点和B点的消息坐标,就可以完成一系列的行为树流程了。
- 1.到达A点上方
- 2.下降至A点
- 3.等待3秒(执行抓取操作)
- 4.抬升回到A点上方
- 5.移动至B点上方
- 6.下降至B点
- 7.等待3秒(执行放置操作)
- 8.抬升回到B点上方
- 9.返回home
那么整个过程的运动规划使用的是moveit,需要在节点中调用moveit的API。
4.通过手眼标定矩阵完成坐标转化
这里的手眼标定过程是由qgx同学来完成的,我们只需要使用生成的转换矩阵,将识别药板和黑框的节点中药板相对于相机的坐标,转化为药板相对于机器人基坐标系下的坐标即可。
这里就写一下手眼标定是什么原理吧,希望能用我自己的话讲明白:机械臂能做到的是,发送一个相对于基坐标系的位姿,机械臂末端就会到达这个位姿,但是我们识别到的是药板相对于相机的位姿,而我们需要的是药板相对于基坐标系的位姿。这里我们就可以想一个问题,既然我现在保证头部摄像头的位置是不动的,那么它相对于基坐标系的位置也是固定的,所以说一个物体他在相机中识别到的任何一种位姿,一定可以通过某个固定的转换矩阵,来转换为相对于基坐标系下的坐标。
所以手眼标定的过程,其实就是求这个固定的转换矩阵的过程。
把标定板绑在机械臂末端,标定板移动到某个位置,相机识别到位姿,我们又已经知道标定板相对于基坐标系的位姿,重复上述的过程5组左右,就可以求出这个转换矩阵了,其实他的本质就是一个解方程组的过程。
5.最后的整合
最后,将发送话题的名称和消息的格式,调整至与运动控制节点规定接收的一致,单位和角度制设置一致,OK,大功告成。
完整流程如下:
启动相机节点
ros2 launch realsense2_camera rs_launch.py进入工作空间并编译,设置环境变量
cd robot_ws
colcon build
source install/setup.bash启动运动控制节点,会提示开始接收A点和B点坐标
ros2 run bt_task_manager_ros2 task_scheduler_node启动识别药板节点
ros2 run simple_detector simple_detector_node启动识别黑框节点
ros2 run simple_detector recognize_node这样,机械臂就会开始从到达抓取位置再到放置位置的一系列流程了。
这样,这个项目的技术总结到这里就结束了,虽然说写起来还挺顺,但是中间兜兜转转遇到了多少问题,在图书馆和研究院熬过了多少个不眠夜,只有真正走过这一遭的人才能懂吧。希望几年之后我再看到这篇文章的时候,还会想起这一学期与这个项目的种种羁绊,想起在大二上那个不知天高地厚,渴求成功的少年。
以终为始,共勉。